Risk-Based Prioritization, Not Severity-Based Panic
why risk based.
As of 2026, and with the advancement of AI in offensive security and SAST, CVE volume is increasing, and for the subset of vulnerabilities that attackers do exploit, the exploitation window is shrinking. That combination creates a prioritization problem: teams have more findings to process, but less time to identify the ones that actually matter.
Examining the below reference from the Zero Day Clock, we can see 2 major trends that support this claim:
Time to Exploit 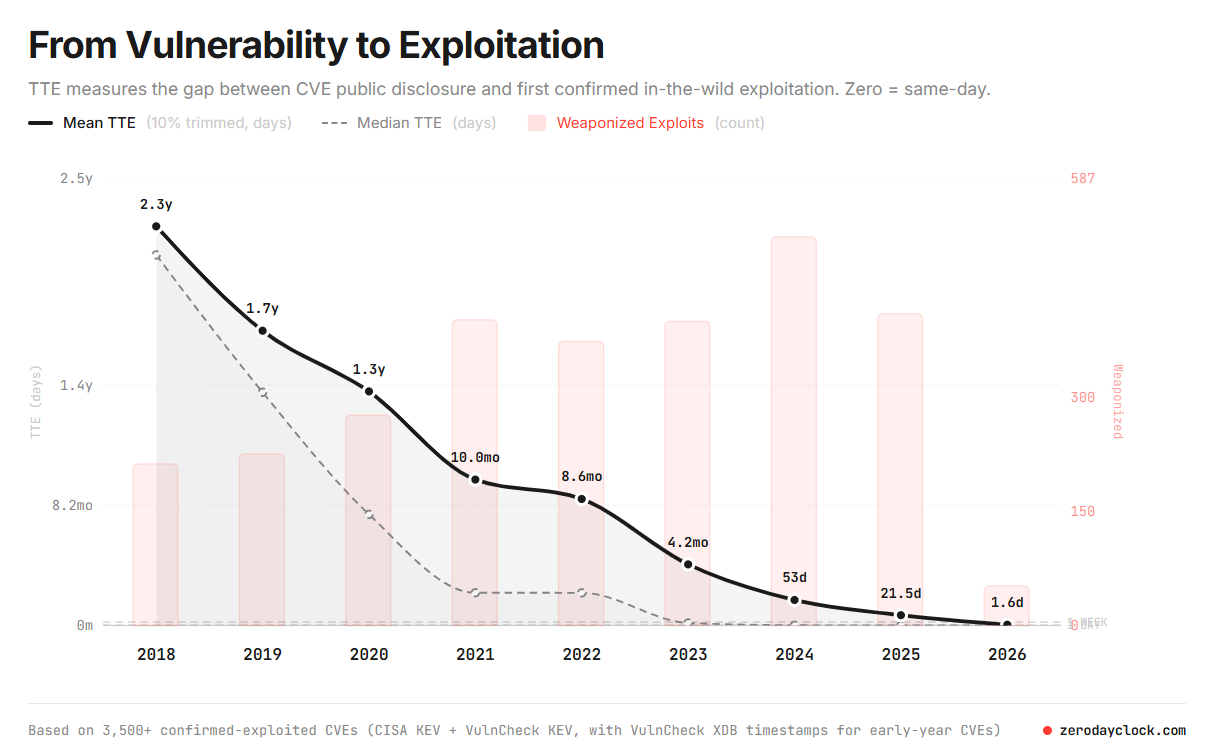
Exploit Rate 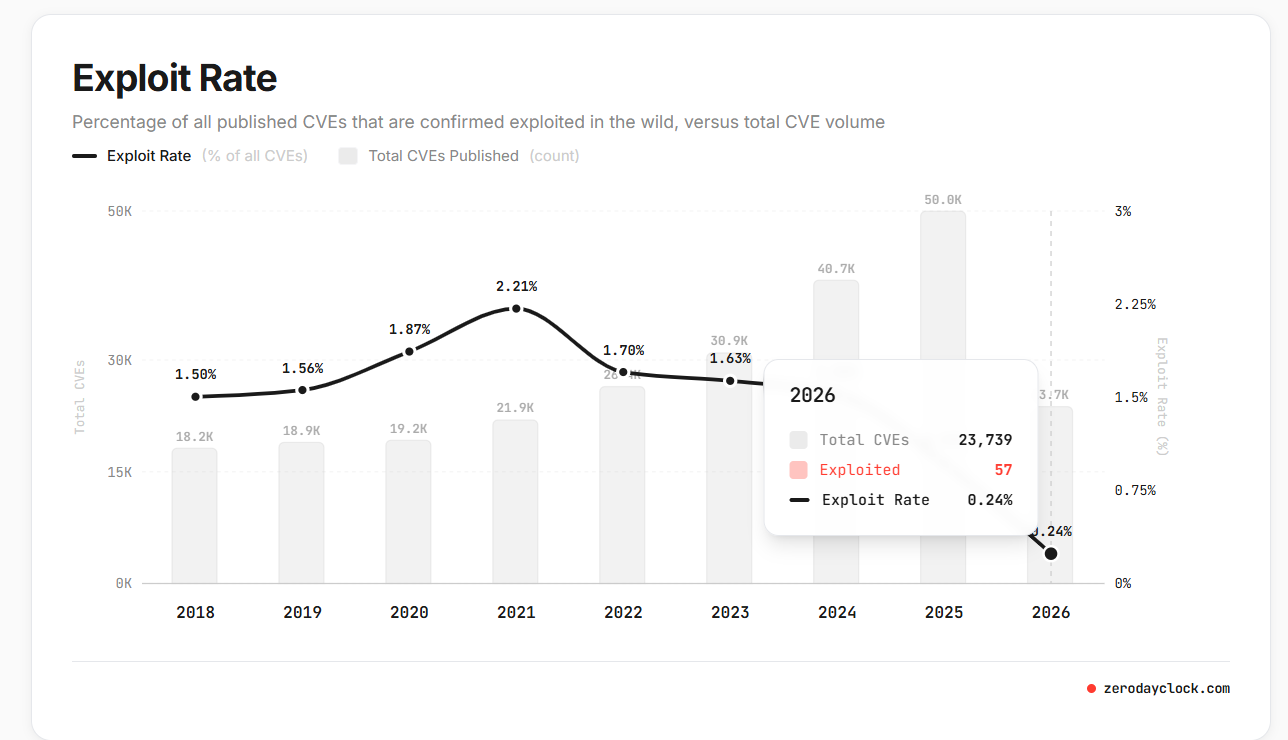
- The time to exploit a CVE is nearing <24 hours, and it will reach it sooner than expected. (At the time of writing, the figure had already moved from roughly 2.4 days to 1.6 days within 2 weeks, reinforcing how quickly the trend is changing.).
- The exploit rate is on a downward trend. There are too many CVEs reported and only a fraction of them are being exploited.
This means that organizations are being flooded with vulnerabilities at a rate they cannot handle, and where they most definitely cannot effectively filter through the noise and focus on remediating the exploitable and critical CVEs. Hence, the panic.
Combining these 2 factors, it is apparent that relying on CVE severity/CVSS scores alone is not sufficient. To be able to filter through the flood of CVEs, teams should focus on understanding the risk posed by each CVE, and prioritize based on that. CVSS scores are a good starting point, but they do not take into account the specific context of the organization. CVSS even misses (or under represents) some of the most critical factors that affect the risk posed by a CVE such as:
- The presence of an exploit in the wild.
- Visibility of the vulnerable asset to the internet.
- If the vulnerable components process untrusted data.
- The presence of compensating controls that mitigate the risk posed by the CVE.
Hence, it seems like the better idea is to take a risk-based approach to vulnerability management, and not just rely on severity-based panic. We can even see that the industry is moving towards this approach, namely NIST is now only looking at CVEs based on their own risk-based criteria. NIST’s 2026 NVD operations update
UPDATE: As of June 2026, CISA has issued BOD 26-04, requiring US Federal Civilian Executive Branch agencies to adopt a risk-based approach to vulnerability management and remediation. The directive uses an SSVC-informed decision tree to assign remediation timelines based on factors such as exploitation status, exposure, and potential impact, rather than relying on severity alone. CISA’s 2026 vulnerability management update
severity is not priority.
A common mistake in vulnerability management is treating severity as the same thing as priority.
Severity describes the technical characteristics of a vulnerability. Priority should describe what the organization should do about it. Those are related, but they are not the same.
A Critical CVSS vulnerability in an isolated internal component with no exploit path may deserve attention, but it may not be the first thing the team fixes. A High vulnerability in an internet-facing authentication flow with public exploit code and customer data exposure may be the real emergency.
That is why severity should be treated as an input into the decision, not the decision itself.
defining risk-based prioritization.
Risk-based prioritization is the process of assessing the risk posed by each vulnerability and prioritizing them based on that risk. This involves taking into account the specific context of the organization, such as the assets that are vulnerable, the potential impact of an exploit, and the likelihood of an exploit being successful, etc…
This approach allows organizations to focus their resources on the vulnerabilities that pose the greatest risk, rather than trying to remediate every vulnerability regardless of its severity.
Technically, this takes the form of a matrix scoring system, where each CVE is scored based on the various factors that affect its risk, and then prioritized based on that score.
the matrix.
The matrix is a simple 2 vector scoring system, where one vector represents the likelihood of an exploit being successful, and the other vector represents the potential impact of an exploit. (This is not a rule of thumb and effectively each axis can represent a different factor based on the organization’s context, but this is the most common approach).
defining the vectors.
the Y axis: likelihood.
likelihood is exactly what the word implies.
“How likely is it that this vulnerability will actualize?”
in the world of CVEs, this is affected by the following factors:
- KEV status: if there is a known exploit in the wild
- PoC status: if there is a public PoC and how mature/automatable it is.
- EPSS score: lower EPSS score means that the CVE is less likely to be exploited.
- Exposure of the vulnerable asset: if the vulnerable asset is not exposed, then it is less likely to be exploited. e.g: a critical CVE found in an internal application that is not exposed to the internet is less likely to be exploited than a critical CVE found in a public facing application.
These are just some of the factors that affect the likelihood of an exploit being successful, and there are many more factors that can be taken into account based on the organization’s context.
Example Scoring:
| Likelihood | Score | Meaning |
|---|---|---|
| Very High | 5 | There is a known exploit in the wild, and the vulnerable asset is exposed to the internet. Or EPSS score is very high and there is a public PoC that is mature and automatable |
| High | 4 | There is a public PoC, and the vulnerable asset is exposed to the internet |
| Medium | 3 | There is a public PoC, but the vulnerable asset is not exposed to the internet |
| Low | 2 | There is no public PoC, but the vulnerable asset is exposed to the internet |
| Very Low | 1 | There is no public PoC, and the vulnerable asset is not exposed to the internet |
This is just a high level example of how the likelihood can be scored, and is not limited to ONLY the above factors.
the X axis: impact.
for impact, the question to ask is:
“What is the damage if this vulnerable component is exploited?”
Now, at first, this metric might sound generic, but the idea here is to ground that question in the context of the organization. Meaning, we need to look at our application and understand what is considered “Crown Jewels” and “Critical Systems” for our organization. One way this can be done, is through classification. My approach was using 4 metrics:
- Data Classification: Classify data based on sensitivity/importance. Once data is classified then the impact can be quantified.
- Blast Radius and Availability: Would an exploit of this CVE lead to a large blast radius? would it lead to a DoS of a single microservice, or would it lead to a DoS of the entire application?
- Regulatory Impact: would an exploit of this CVE lead to a regulatory violation? e.g: if the CVE is found in a component that processes credit card data, then it is more likely to lead to a regulatory violation than a CVE found in a component that does not process sensitive data.
- Financial Loss: would an exploit of this CVE lead to a financial loss? e.g: if the CVE is found in a component that processes payments, then it is more likely to lead to a financial loss than a CVE found in a component that does not process payments.
These are just some of the factors that affect the impact of an exploit, and there are many more factors that can be taken into account based on the organization’s context.
Example Scoring:
| Impact | Score | Meaning |
|---|---|---|
| Negligible | 1 | Negligible business or technical impact |
| Low | 4 | Limited component-level impact |
| Medium | 9 | Meaningful service, data, or user impact, but not critical |
| High | 16 | Critical business function, sensitive data, or broad blast radius |
| Critical | 25 | Crown-jewel system, regulatory exposure, major financial/customer impact |
scoring. 5x5 or 5x25?
Many organizations use a traditional 5×5 risk matrix, where likelihood and impact are both scored from 1 to 5. While simple, it assumes both factors should carry equal weight.
For vulnerability management, I prefer a 5×25 model. Likelihood remains on a 1–5 scale, while impact is weighted from 1–25 to better reflect business criticality. In practice, a highly exploitable vulnerability in a low-value internal component shouldn’t automatically outrank a lower-likelihood issue affecting customer data, authentication, payment flows, or core availability.
The wider scoring range also reduces ties, resulting in clearer prioritization and more meaningful remediation queues.
examples of the matrix.
5x25 risk matrix
| Likelihood \ Impact | 1 | 4 | 9 | 16 | 25 |
|---|---|---|---|---|---|
| 5 - Very High | 5 | 20 | 45 | 80 | 125 |
| 4 - High | 4 | 16 | 36 | 64 | 100 |
| 3 - Medium | 3 | 12 | 27 | 48 | 75 |
| 2 - Low | 2 | 8 | 18 | 32 | 50 |
| 1 - Very Low | 1 | 4 | 9 | 16 | 25 |
A possible interpretation is: 1-20 = Low, 21-45 = Medium, 46-80 = High, and 81-125 = Critical. These bands should be tuned to the organization’s risk appetite.
matrix in action.
Take for example an SCA scan reports 200 vulnerabilities, including 10 Critical findings. Engineering has capacity for 10 developer-days this sprint.
A severity-first approach would assign the entire sprint to the Critical findings.
Using the risk matrix, however, you might discover that:
- 6 Critical findings affect internal tools with no realistic attack path.(Low impact, low likelihood)
- 3 High findings impact customer authentication and have public exploit code. (High impact, High likelihood)
- 1 Medium finding affects a payment service that is internet-facing and already appears in CISA KEV. (Critical impact, Very High likelihood)
Instead of spending all 10 developer-days on the Critical findings, the matrix prioritizes the vulnerabilities that present the greatest business risk, regardless of their CVSS score.
the point.
The point is not to replace CVSS with another perfect score. The point is to avoid treating severity as a decision. Severity is input. Risk is the decision layer. Security maturity isn’t/Shouldn’t be measured by how many vulnerabilities you fix. It’s measured by whether you fixed the right ones.
The above writeup is heavily focused on CVEs, but the same approach can be applied to any vulnerability, even if it does not have a CVE identifier. e.g.: For organizations that run regular internal/external pentests, the same approach can be applied to the pentest findings.
This post is part of Jad’s Cybersecurity Blog.